How DNS Resolution Works (Using dig to See What’s Actually Happening)
In the last article, we discussed various network devices and the basics of how a request travels across the internet.
If you’re interested, you can read it here:
Understanding Network Devices: How the Internet Reaches Your Device
In this article, we’ll focus on DNS - what it is, why it exists, and how name resolution actually happens under the hood.
What Is DNS and Why Name Resolution Exists
DNS stands for Domain Name System.
As the name suggests, it is a system that holds information about domain names.
Domain names are simply the website names we type into applications - like google.com, youtube.com, etc.
In computer networks, all communication happens using IP addresses.
IP addresses are used on the internet to identify devices in the network. They do not have human-friendly names.
Just like our houses or flats have an address, IP addresses serve the same purpose for computers and network devices (Layer 3 and above).
At first glance, DNS feels similar to a phonebook - and that analogy works - but in a more accurate sense, it behaves closer to a distributed database.
Phones understand numbers, not names.
When you select a person’s name in your phone, the phone application automatically translates that name into a phone number.
DNS does the same thing for the internet.
You type a website name, and DNS returns the corresponding IP address to your application (browser, curl, Postman, etc.), which is then used to make the actual network request.
DNS is a massive system.
Think about an IPL final or a big e-commerce sale. A lot of preparation goes into handling that traffic. But every single user visiting those platforms must first resolve the domain name.
Even then, the comparative load on DNS is surprisingly low.
That’s the beauty of how this system is designed.
Most of the complexity is hidden from us by browsers and tools - but we do have ways to see what’s going on underneath.
Introducing dig
dig is a tool used to interact directly with DNS and inspect its responses.
It’s a CLI tool.
Here’s what happens when we run:
dig google.com
;; QUESTION SECTION:
;google.com. IN A
;; ANSWER SECTION:
google.com. 183 IN A 142.251.221.142
This tells us that google.com has an A record pointing to the IP 142.251.221.142.
That is a public IP for Google.
Try this yourself:
Run
dig google.comCopy the IP from the output
Paste it directly into your browser
Observe what happens.
DNS Is Not a Simple Database Lookup
At a surface level, DNS might look like a simple database query:
“Give me the IP for this domain.”
But that’s not the reality.
Imagine storing hundreds of billions of records and querying them globally for billions of devices, all in near-real time.
That approach wouldn’t scale.
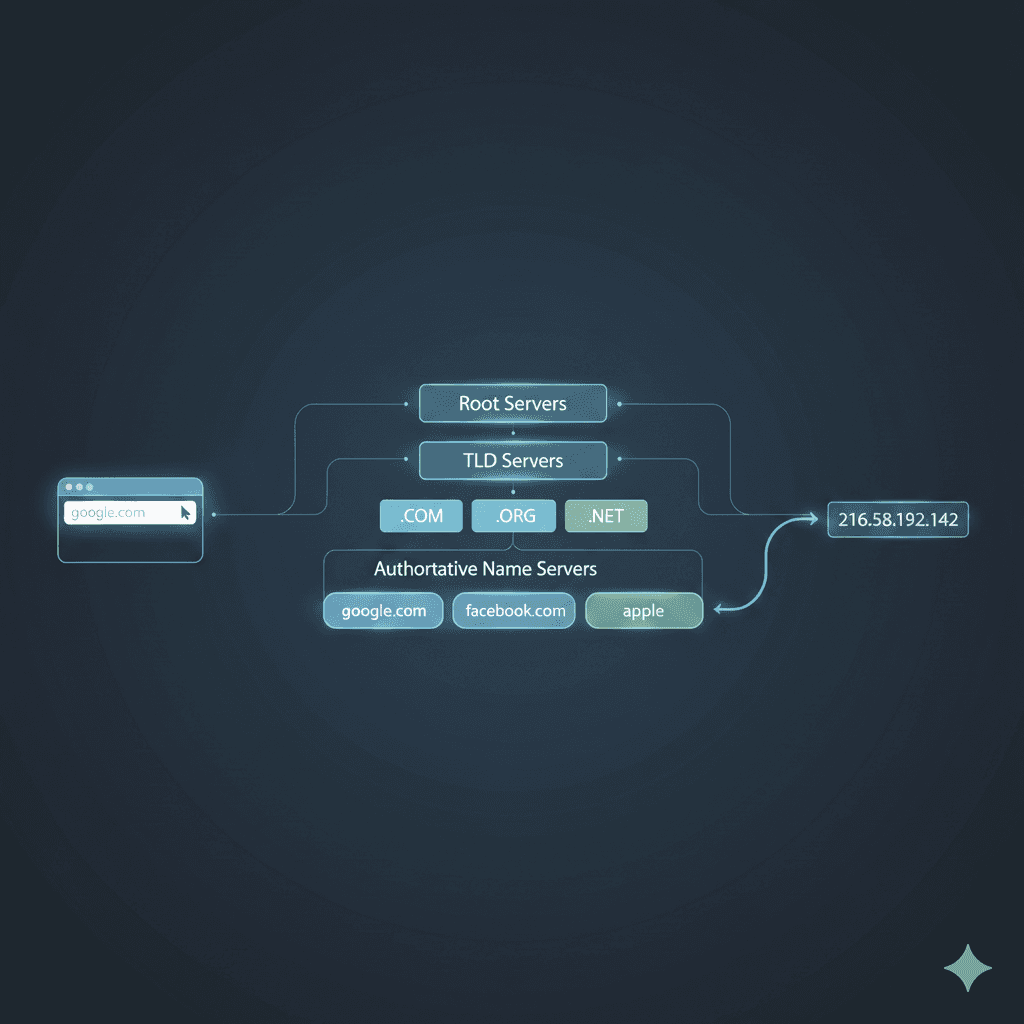
The Distributed Structure of DNS
DNS works because it is distributed.
From top to bottom, the hierarchy looks like this:
Root Servers → TLD Servers → Authoritative Name Servers
Each layer has a very specific responsibility.
Root Name Servers
Root servers are the top-most servers in the DNS hierarchy.
They do not store IP addresses for websites.
Instead, they store information about TLD (Top Level Domain) servers.
Based on the domain you’re trying to resolve, the root server directs you to the appropriate TLD server.
There are 13 root server identities globally.
We can see them using:
dig . NS
This returns entries like:
a.root-servers.net.
b.root-servers.net.
...
m.root-servers.net.
These are the starting points for DNS resolution.
TLD Name Servers (.com, .in, .dev, etc.)
TLD servers store information about authoritative name servers.
Examples of TLDs:
.com.in.dev.ai
To inspect .com TLD servers, we can run:
dig com NS
This returns servers such as:
a.gtld-servers.net.
b.gtld-servers.net.
...
m.gtld-servers.net.
At this layer, DNS still does not return IP addresses for websites.
Instead, it tells us where to find the authoritative servers for a given domain.
Authoritative Name Servers
Authoritative name servers are the servers that actually store the DNS records for a domain.
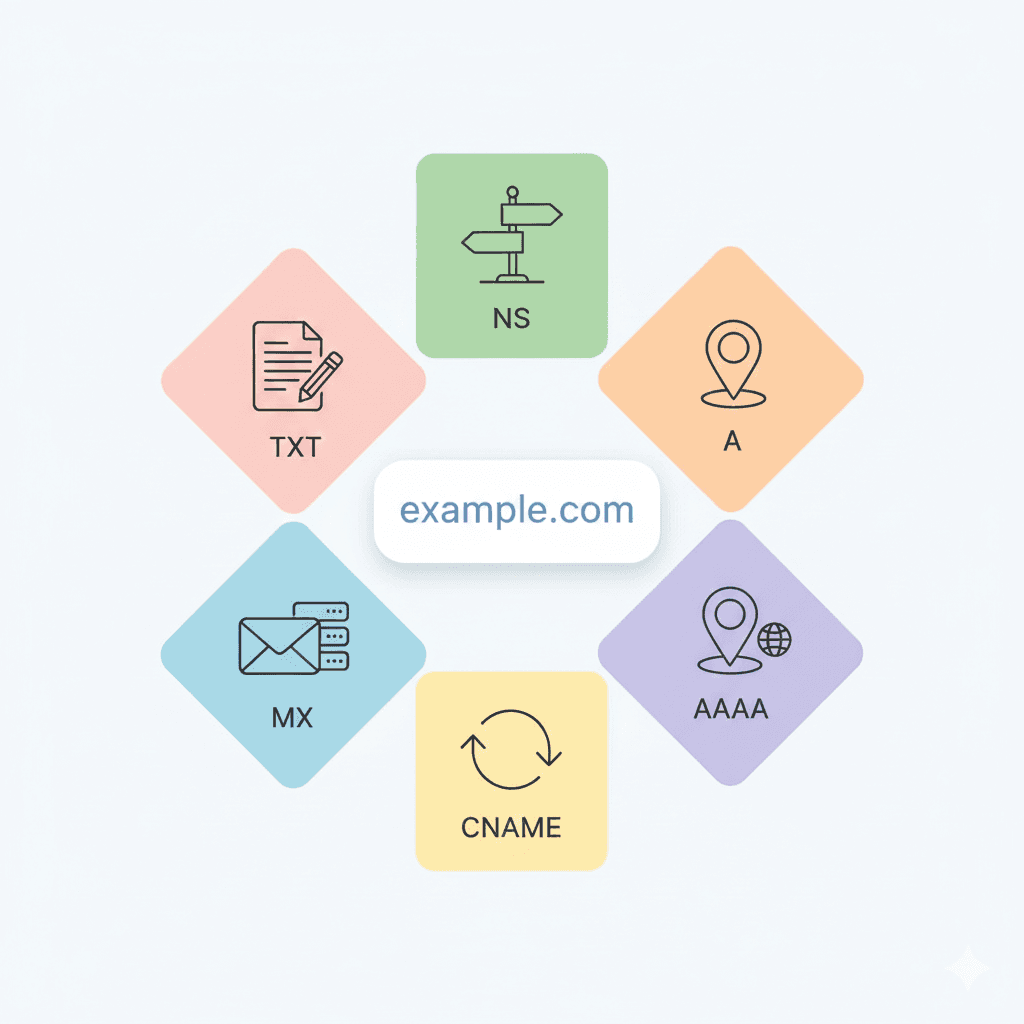
This includes:
A records
AAAA records
(other record types not discussed here)
To know more about record types, can check article: How Does a Browser Know Where a Website Lives
For google.com, we can inspect them using:
dig google.com NS
This returns:
ns1.google.com.
ns2.google.com.
ns3.google.com.
ns4.google.com.
These are the servers that finally know the IP addresses for google.com.
Querying one of these servers gives us the IP we need.
The Full DNS Resolution Flow (google.com)
If we assume no caching, DNS resolution for google.com follows this path:
Root Server → .com TLD Server → google.com Authoritative Server → IP
This can be visualized using:
dig google.com +trace
The output clearly shows:
Root servers responding first
.comTLD servers responding nextGoogle’s authoritative servers responding last with the A record
This trace represents the entire DNS resolution chain.
The Role of the Recursive Resolver
The client (browser or application) does not perform all these steps itself.
There is another component in between called the recursive resolver.
Flow looks like this:
Browser / App → Recursive Resolver → DNS Hierarchy → Resolver → App
The application sends a DNS query to the recursive resolver.
The resolver:
Talks to root servers
Talks to TLD servers
Talks to authoritative servers
Collects the final answer
Returns the IP to the application
Caching in DNS
Caching is one of the most important reasons DNS performs so efficiently.
Caching happens at multiple levels:
Browser
Operating System
Recursive Resolver
Resolvers are heavily relied upon, so caching at this layer has a huge impact on performance.
Operating systems also have their own DNS configurations, which are checked before external resolution.
This is rarely used in day-to-day browsing but is extremely useful for personal testing and overrides.
Note: The command outputs mentioned are trimmed to highlight main part of the response. The actual response for the commands discussed will have much more details.