How Git Works Internally: Building a Mental Model
Most Git tutorials focus on commands.
This article focuses on what actually happens inside Git when we run those commands.
Before going forward with this article, you can go throgh below for better understanding
Why Version Control Exists: The Pendrive Story Every Developer Has Lived
We’ll explore:
What the
.gitfolder is and why it existsHow Git stores data internally using objects
Why Git commits are called snapshots
How Git tracks changes efficiently
All examples below are based on hands-on experimentation, not theory.
The .git Directory: The Heart of Git
When we initialize a Git repository:
git init
Git creates a .git/ directory.
/home/app # ls -la
drwxr-xr-x 6 root root 4096 Jan 17 12:59 .git
Why does .git exist?
.git/stores all information about version trackingThis includes:
commit history
branches
file snapshots
metadata
If the
.git/directory is lost:all Git history and tracking is lost
files remain, but Git has no memory of them
From Working Directory to Commit
Any change you make flows through these stages:
Working Directory
- New file or modified file
Staging Area
- Changes selected to be recorded
Commit
- A snapshot of the project is stored permanently
At a high level:
Working Directory → Staging Area → Commit
To really understand Git, we need to zoom into what a commit actually contains.
A Simple Repository Walkthrough
Initialize a repo
mkdir app
cd app
git init
Create a file:
touch app.txt
git status
Git shows the file as untracked.
First Commit
git add app.txt
git commit -m "Create App file"
This creates the first commit (root commit).
Checking history:
git log
We now see a commit chain starting point.
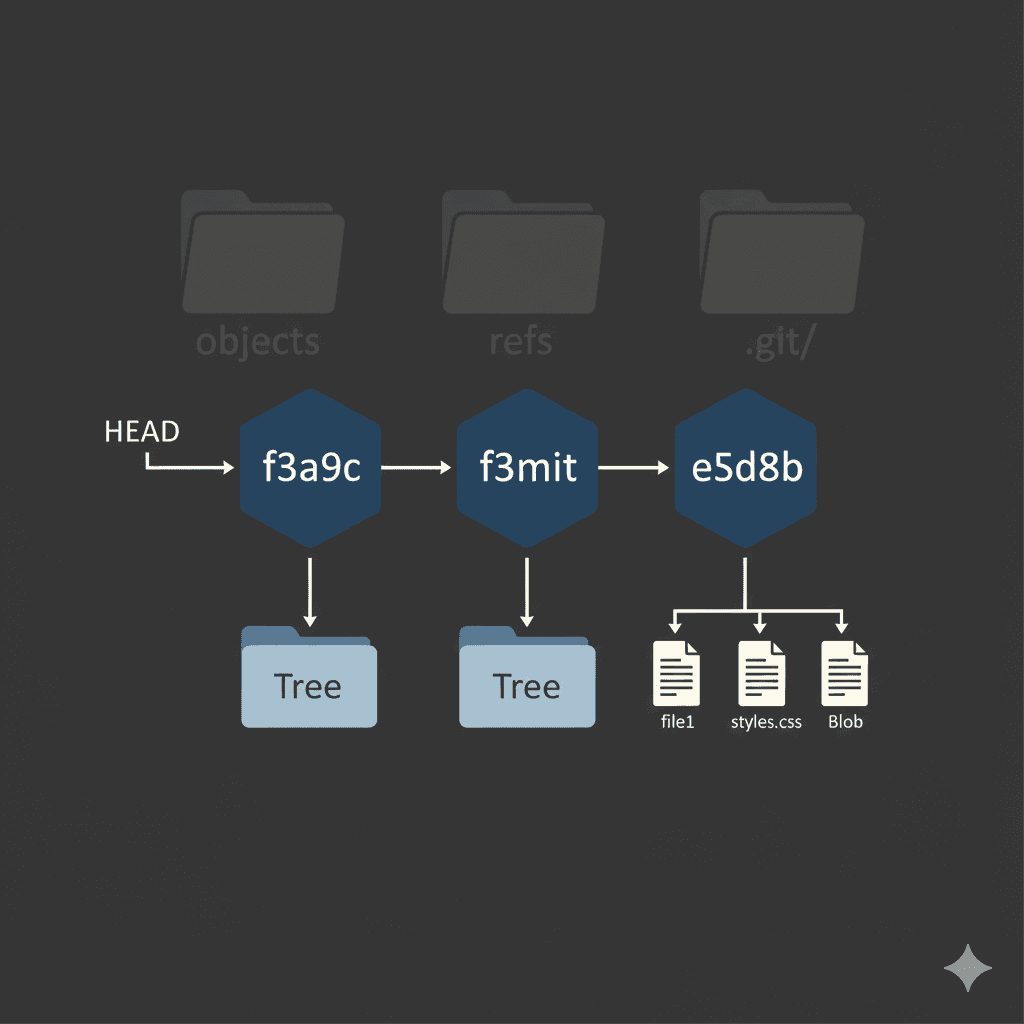
Git Commit History Is a Chain
Each commit:
Has a unique hash
Stores a reference to its parent commit
This forms a linked structure:
commit → parent → parent → ...
To inspect a commit internally:
git cat-file -p <commit-hash>
Example output:
tree bda94d5297b34fc5391112596c3f6b2926891352
parent 37087ac939b14f57c7b223d0903ffb5cb4d1896a
author ...
committer ...
Add Line 2 in app and new Readme file
What this tells us
A commit stores:
a reference to a tree
a reference to its parent
author and message
So the commit itself does not store file contents directly.
Tree Objects: Representing Folder Structure
Let’s inspect the tree object:
git cat-file -p <tree-hash>
Output:
100644 blob 3485b695ca9834fcdc2bf439f1c12109b8b54634 README.md
100644 blob 40f9bae6a2073fc65d8e2b618b73534a84317ad7 app.txt
A tree:
represents a directory
maps filenames → blob hashes
can reference other trees (for subdirectories)
Blob Objects: Actual File Content
Inspecting a blob:
git cat-file -p <blob-hash>
Output:
This is line 1
This is line 2
A blob:
stores only file content
has no filename information
same content → same blob hash
Why Commits Are Snapshots
After adding a new line and committing again:
echo "This is line 3" >> app.txt
git commit -am "Add line 3 in app"
Inspecting the new commit shows:
a new tree
a new blob for
app.txtsame blob hash for
README.md
This proves:
Each commit represents a full snapshot
Unchanged files reuse existing blobs
Git optimizes storage automatically
Git does not save “changes” - it saves states.
Exploring the .git Directory
Listing .git/:
ls .git/
output:
HEAD
objects
refs
index
logs
...
For internal understanding, we focus on:
HEADrefsobjects
HEAD and Branches
cat .git/HEAD
output:
ref: refs/heads/master
HEAD points to:
a branch
which points to a commit
Inspect branch ref:
cat .git/refs/heads/master
output:
28c6f9787e22397050b706616d20e1c8cccbdc89
Creating a new branch:
git checkout -b feature
Now:
refs/heads/
├── master
└── feature
Both branches initially point to the same commit.
This shows:
A branch is just a file containing a commit hash.
Objects Directory: Where Git Stores Everything
ls .git/objects/
output:
20 28 34 37 40 9f bd e9 f7 info pack
Each folder:
is named using the first two characters of an object hash
contains files named with the remaining characters
Example:
ls .git/objects/28/
This object corresponds to the commit we inspected earlier using git cat-file.
So:
blobs
trees
commits
all live together inobjects/
How Git Tracks Changes (Mental Model)
Putting it all together:
git addprepares blobs
updates the staging area
git commitcreates a tree from staged blobs
creates a commit pointing to that tree
links to the parent commit
Branch refs move forward
Old objects remain immutable
Hashes and Integrity
Git uses hashes to:
uniquely identify content
detect corruption
avoid duplicate storage
Same content → same hash
Different content → different hash
Final Takeaway
This exploration shows that Git is:
not magic
not command-driven
but a content-addressed snapshot database
Understanding this internal model makes:
branching intuitive
history manipulation safer
Git errors less scary