Understanding Git: Why It Exists and How We Use It
Search for a command to run...
No comments yet. Be the first to comment.
Revisiting an old assumption from my early days of Kubernetes and realizing where it quietly breaks.
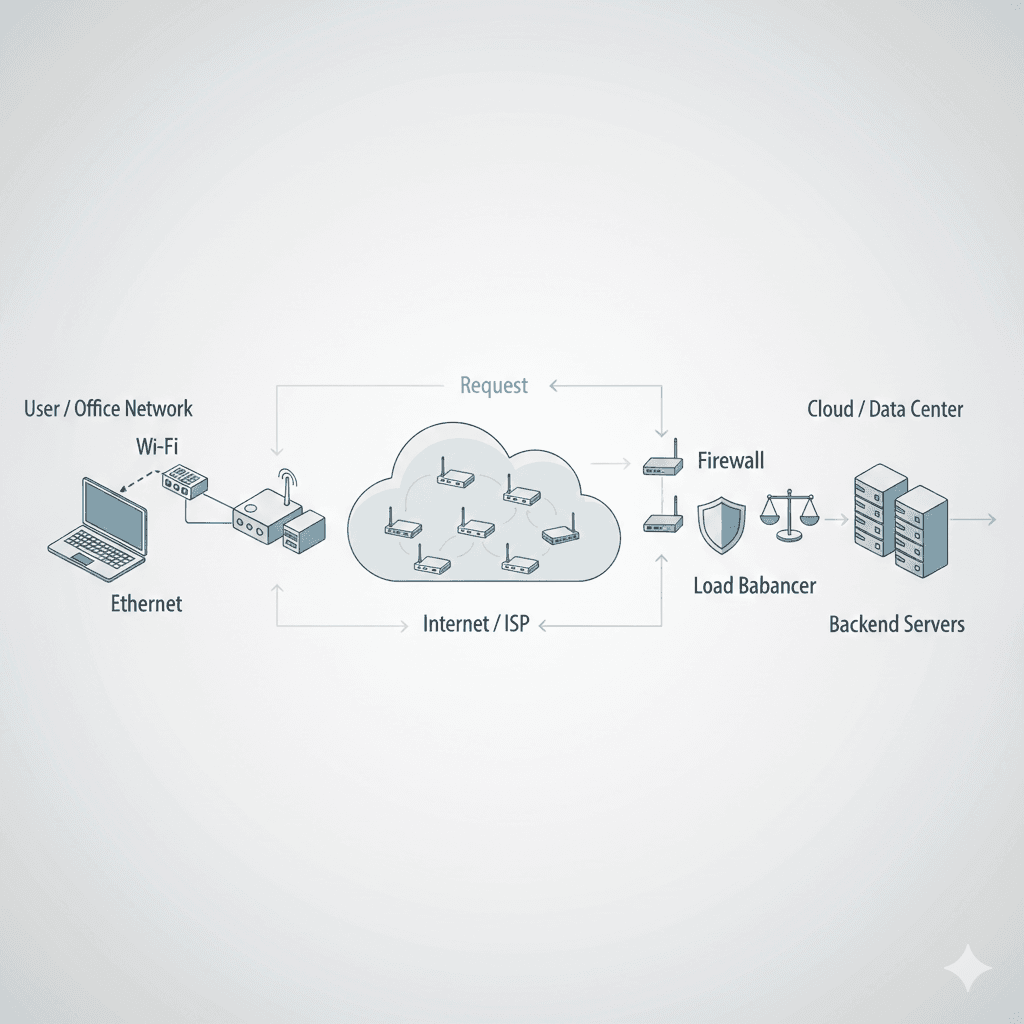
We all use the internet today. The most common way is via Wi-Fi or mobile data, with Wi-Fi being the most prominent.Ever wondered how your device actually gets that Spotify song, YouTube video, or even shows you this particular blog? It often feels l...
In the last article, we discussed various network devices and the basics of how a request travels across the internet. If you’re interested, you can read it here: Understanding Network Devices: How the Internet Reaches Your Device In this article, ...
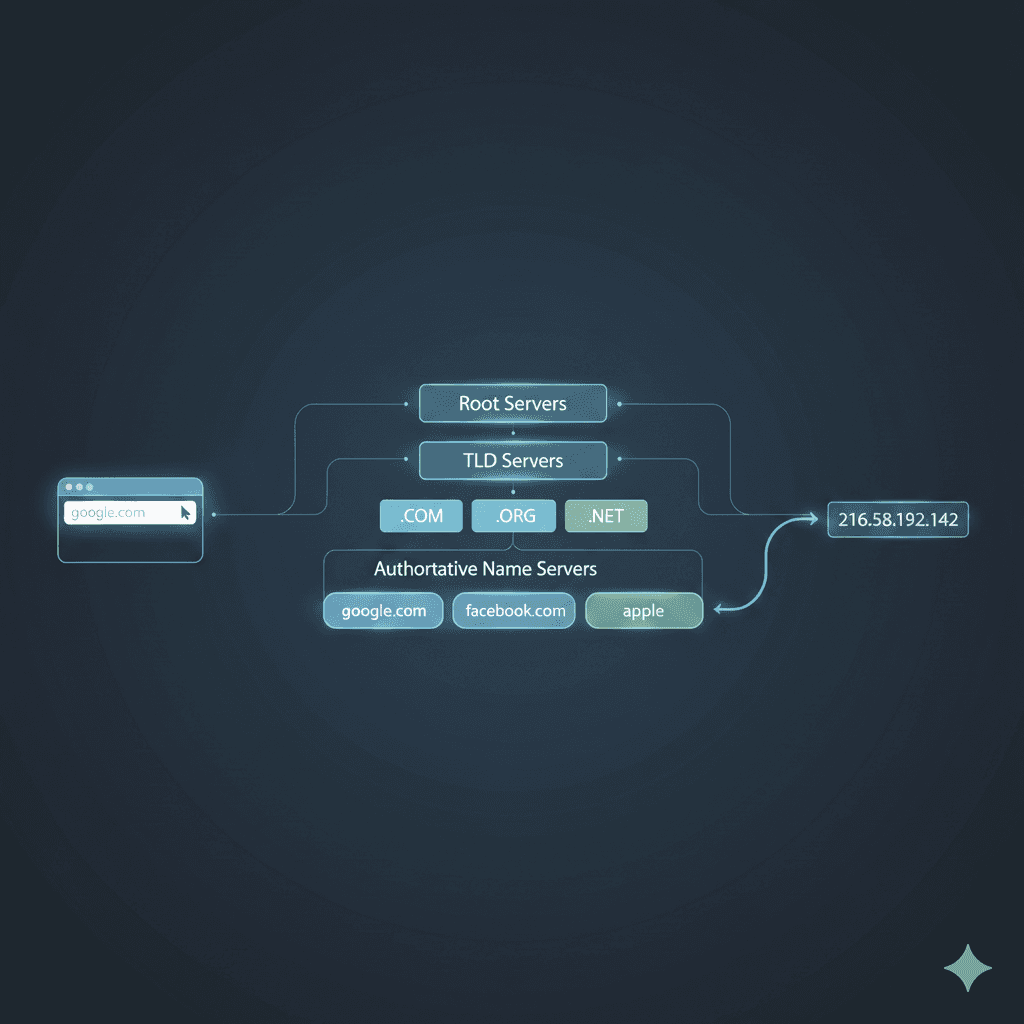
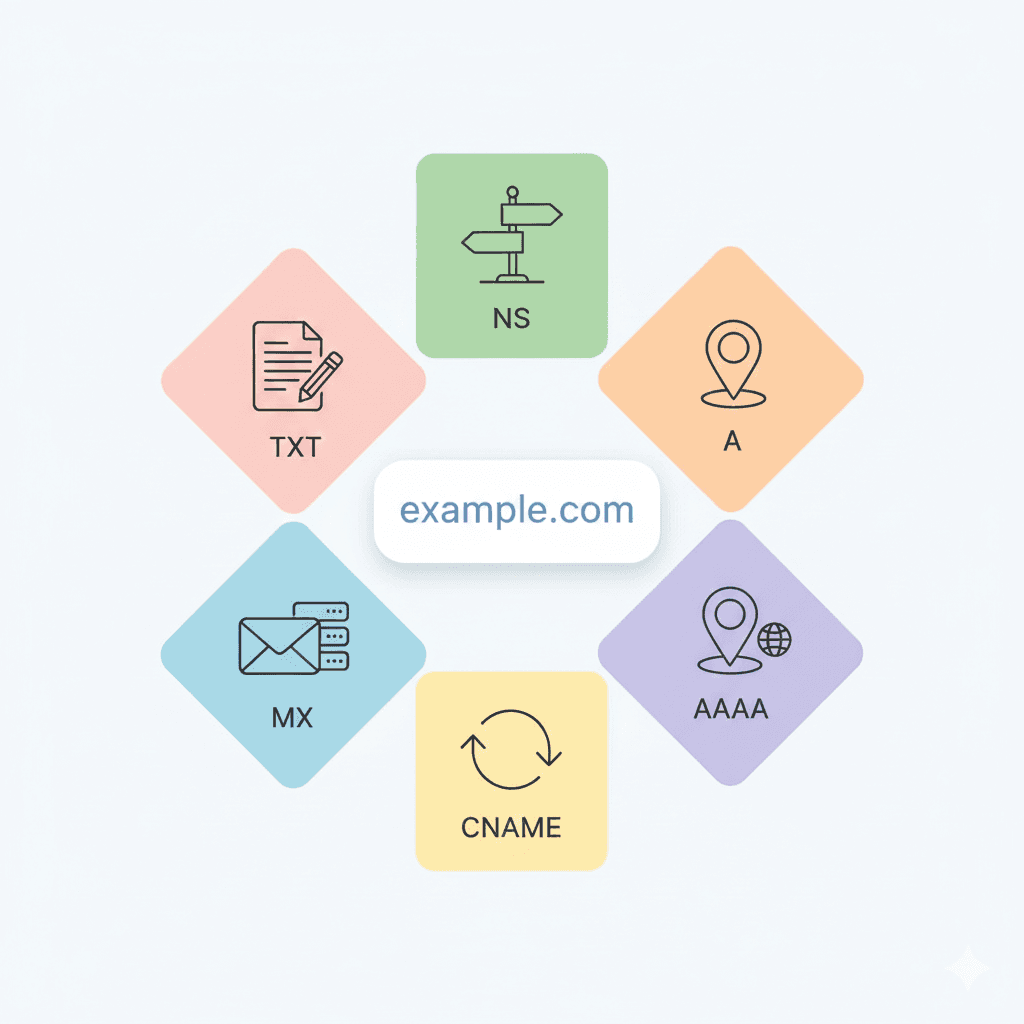
When you type a website name like example.com into your browser, the browser somehow figures out which server on the internet actually hosts that website. But how? This is where DNS comes into play. What is DNS? DNS (Domain Name System) is like a ph...
As a developer, whatever we code eventually gets deployed on a server.A server is nothing but a program that runs somewhere and serves our application to users. Users usually interact with this server through a browser. The browser sends requests to ...
Git is a type of Version Control System (VCS).
It is open source and runs on your local machine.
Before diving into Git, it helps to understand why version control exists in the first place. We discussed the idea of VCS in an earlier article.
Give it a read: Why Version Control Exists: The Pendrive Story Every Developer Has Lived
To understand Git better, let’s first look at how version control evolved over time.
A very common early approach was to maintain multiple copies of the same project locally:
project_1
project_2
project_3
project_final
project_final_2
or sometimes using timestamps.
This approach:
Quickly becomes messy
Leads to confusion over which version is correct
Allows only one person to work comfortably
Lives entirely on a personal device
There is some sense of versioning here, but no real tracking or collaboration.
A better approach was to introduce a central server.
The server stores project files along with their history
Developers fetch a copy, make changes, and push them back
The server manages the code and its history
This solved collaboration issues but introduced new problems:
You always need connectivity to the server
If the central server fails, the project history is at risk
The centralized approach still had limitations.
A decentralized approach solves this by:
Keeping the entire history on every developer’s machine
Allowing work to happen offline
Enabling sync with any peer, remote, or server at any time
Removing a single point of data loss
Git follows this decentralized approach.
Every developer has:
The full code
The full history
Full tracking information
Git runs locally, while platforms like GitHub, GitLab, and Bitbucket are hosting services built on top of Git.
One interesting design choice in Git is that it does not store file diffs.
Instead, Git stores snapshots of the repository at a point in time.
Each commit becomes a reference to the state of the entire repository at that moment.
If you are interested more in this, I have linked an article explaining git internals at the end of this article.
Before version control systems existed, managing projects was error-prone and difficult.
When VCS was introduced, it helped - but early implementations came with their own limitations.
The evolution roughly looks like this:
Projects shared using pendrives, emails, or zip files
The idea of version control introduced
Multiple implementations appeared:
Local VCS
Tracking exists
No collaboration
Everything stays on one machine
Centralized VCS
Easy collaboration
Requires constant server access
Risk if the server goes down
Decentralized VCS (Git)
Full local history
Offline work
Independent collaboration
No single point of failure
Git became popular because it solved the limitations of both local and centralized systems while keeping collaboration fast and reliable.
Below are some common Git terms you’ll frequently come across.
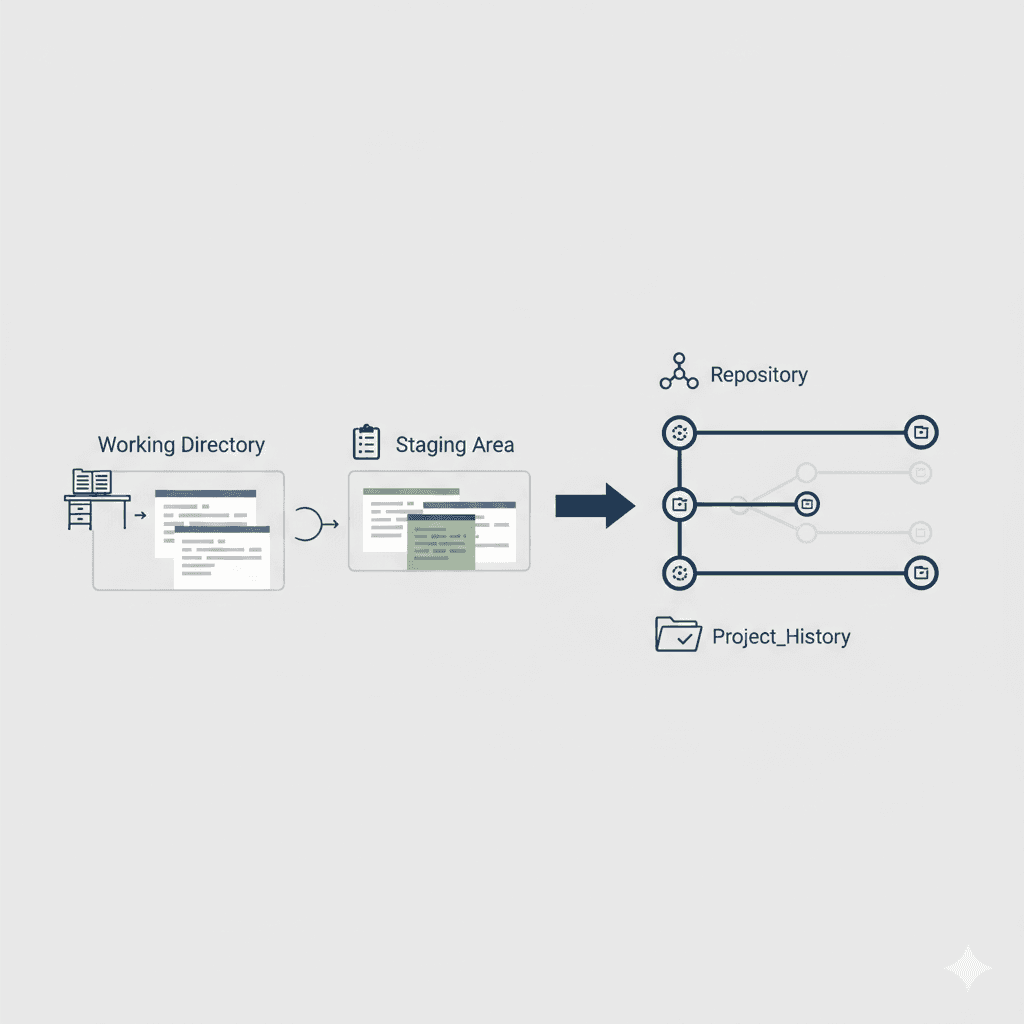
A repository is: Project files + .git directory
The .git directory is where Git stores all tracking and history information.
The working directory is your actual workspace:
Where you see files
Where you edit files
Where changes are made before being tracked
A commit represents:
A snapshot of the code at a given time
A unique hash
A commit message
A chain of commits forms a linked timeline of the project’s history.
The staging area is a special cache-like area that sits between: Working Directory → Repository
It allows you to:
Select specific changes
Decide what should be included in the next commit
A branch is a pointer to a commit.
Using branches allows:
Parallel work
Independent experimentation
Multiple lines of development alongside the original
HEAD is a reference to:
The current branch
The current commit
In simple terms, it tells Git where you are right now.
A remote is another copy of the repository, usually hosted on a server such as GitHub or GitLab.
Below are some commonly used Git commands grouped by purpose.
Initialize a repository
git init
Creates a new .git/ directory.
Check repository status
git status
Shows:
Changed files
Staged files
Untracked files
View commit history
git log
Stage a specific file
git add <filename>
Stage all changes
git add .
Create a commit
git commit -m "message"
Creates a snapshot from the staged changes.
List branches
git branch
Create a new branch
git branch <branch-name>
Switch branches
git checkout <branch-name>
Discard local changes for a file
git restore <filename>
Undo last commit but keep changes staged
git reset --soft HEAD~1
Undo last commit and discard changes
git reset --hard HEAD~1
Below is the article in which we go through practical example to understand git internals, give it a read: